在本章中,我们将研究如何在WordPress中排列类别。 您无法直接在WordPress中排列类别。 因此,您需要安装类别订单插件,以特定方式排列所创建的类别。
步骤(1) – 点击WordPress中的 Posts → Category Order 。 添加 Category Order 插件后,会显示 Category Order 菜单。 您可以在安装插件一章中了解如何安装插件。
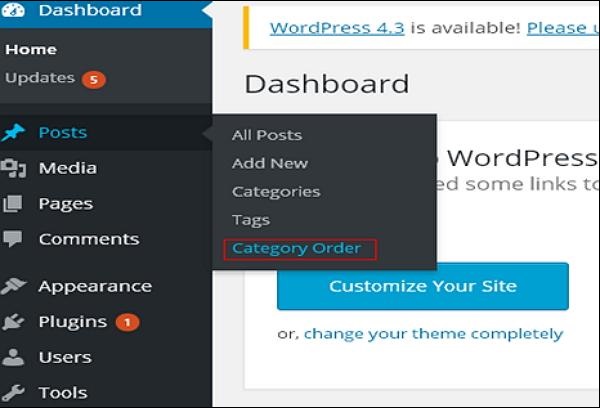
步骤(2) – 在以下屏幕中,您可以看到创建类别部分不正常。
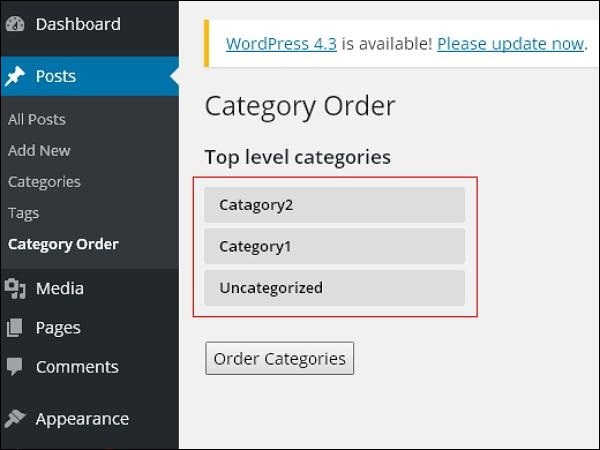
步骤(3) – 现在,您只需根据自己的选择拖动类别,即可重新排列类别。 点击Order categories按钮保存订单类别。






 湘公网安备43020002000238
湘公网安备43020002000238