在本章中,我们将学习如何在WordPress中查看插件。 它可以帮助您启用和禁用WordPress插件。 这将为现有网站添加独特的功能。 插件扩展和扩大WordPress的功能。
以下是在WordPress中查看插件的简单步骤。
步骤(1) – 单击 Plugins → Installed Plugins管理员中的已安装插件。
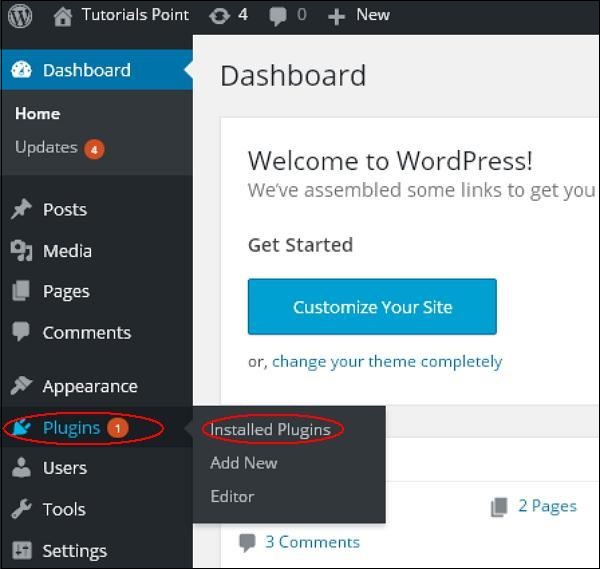
步骤(2) – 您将看到您的网站上现有的插件列表,如下面的屏幕所示。
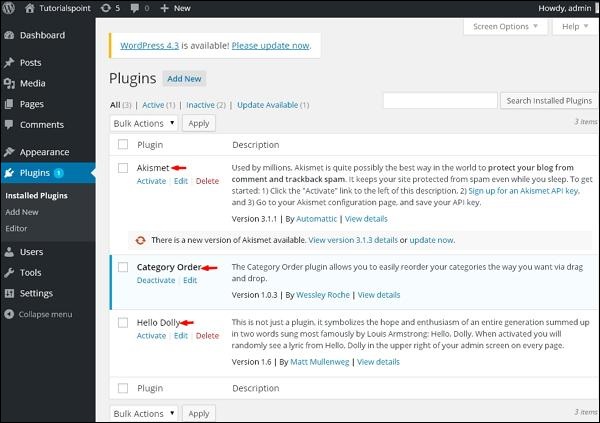
显示插件和说明表。 插件的名称在插件列中定义,插件的简要描述在说明列下定义。
工具栏
以下函数在页面上显示为插件工具栏选项:
Active– 显示网站上的活动插件。
Inactive – 显示网站上已安装但未激活的插件。
Update Available – 显示,如果有一个新版本可用或要求立即更新。





 湘公网安备43020002000238
湘公网安备43020002000238