在本章中,我们将学习在WordPress中删除页面。
以下是在WordPress中删除页面的步骤。
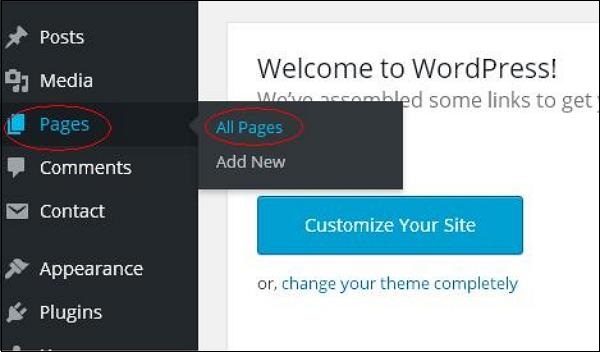
步骤(1) – 点击WordPress中的Pages → All Pages。
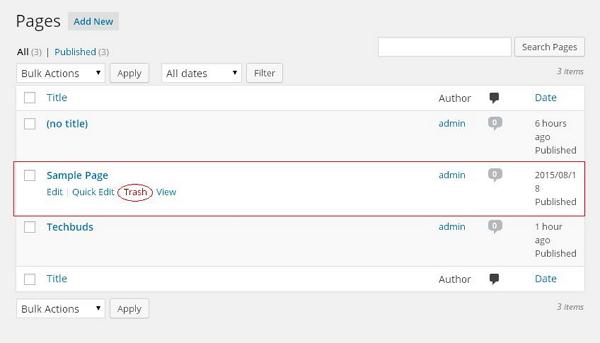
步骤(2) – 您可以删除示例页面(默认情况下在WordPress中创建示例页面)。 当光标悬停在页面上时,几个选项显示在样品页下面。 点击Trash选项可删除该信息。
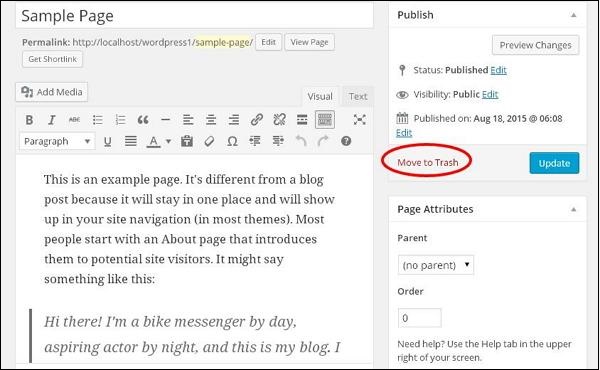
或者,您也可以在编辑或删除页面时直接删除页面,只需点击Move to Trash按钮,如下面的屏幕所示。
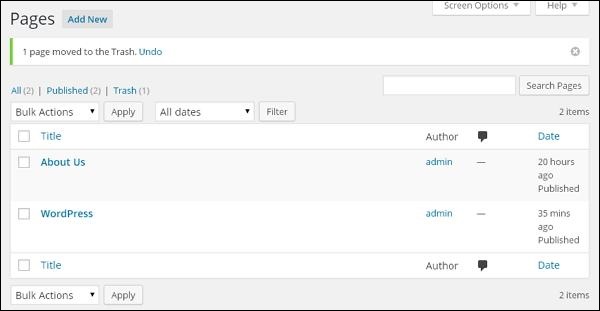
步骤(3) – 要确认您已删除网页,请查看您的网页列表。







 湘公网安备43020002000238
湘公网安备43020002000238